雪崩效应现象
参考资料:
https://github.com/Netflix/Hystrix/wiki
https://www.jianshu.com/p/83a99e183fa5
复杂分布式架构的应用程序有许多依赖,其中每一个在某些时候都会不可避免的发生失败。如果这个主应用没有从那些外部失败隔离,那么就会有被拖垮的风险。
例如,1个应用依赖30个服务,每个服务有99.99%可用,那么预期:
99.9930 = 99.7%的正常运行时间
10亿次请求中有0.3%= 3,000,000次失败
2小时停机时间/月,即使所有的依赖都有很好的正常运行时间现实通常会更残酷。
如果你没有针对整个系统做快速恢复,即使所有依赖只有 0.01% 的不可用率,累积起来每个月给系统带来的不可用时间也有数小时之多。
当一切都ok的请求流看起来是这样的: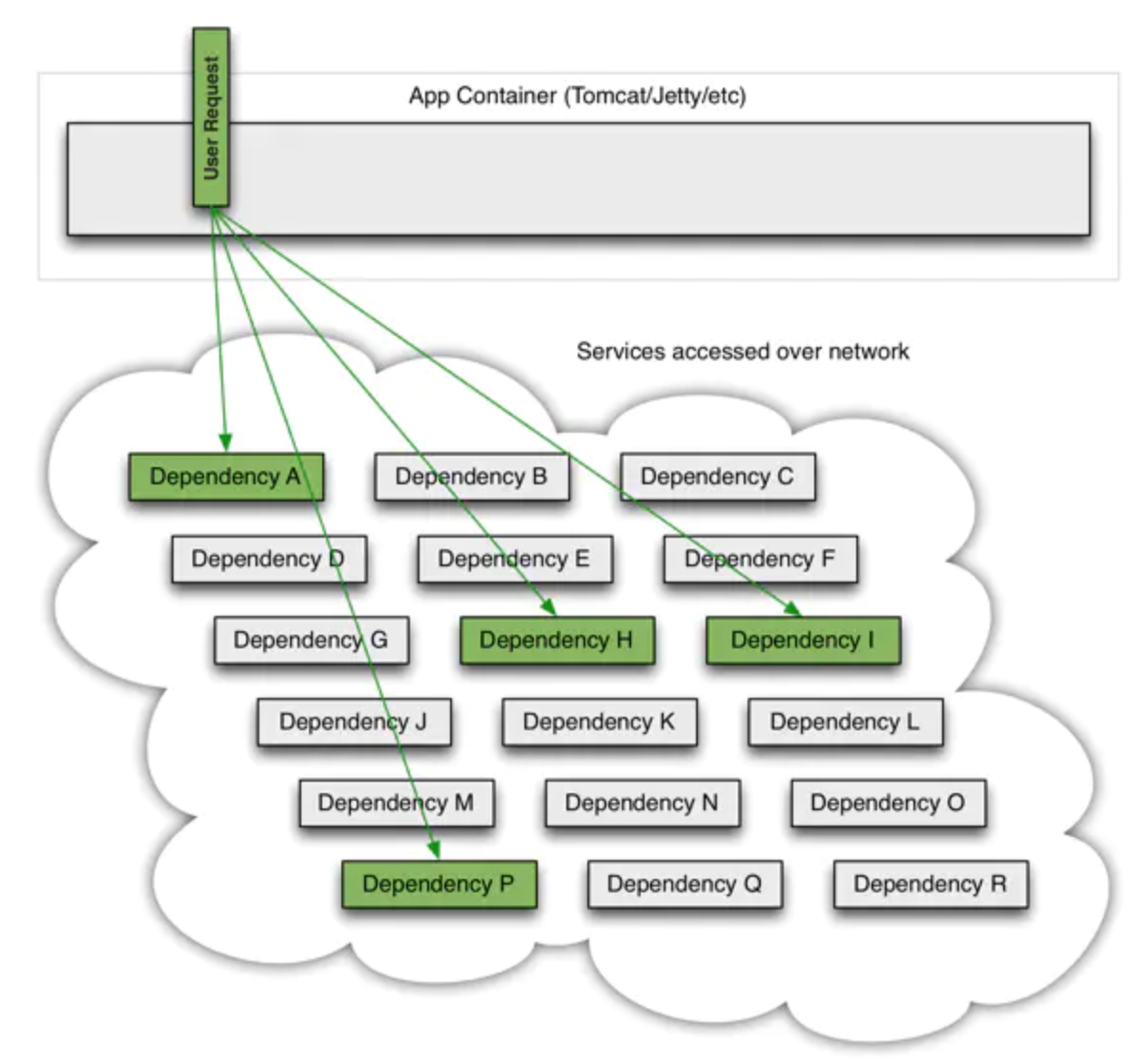
当许多后端系统中的一个成为潜在故障时,可能会阻塞所有用户请求: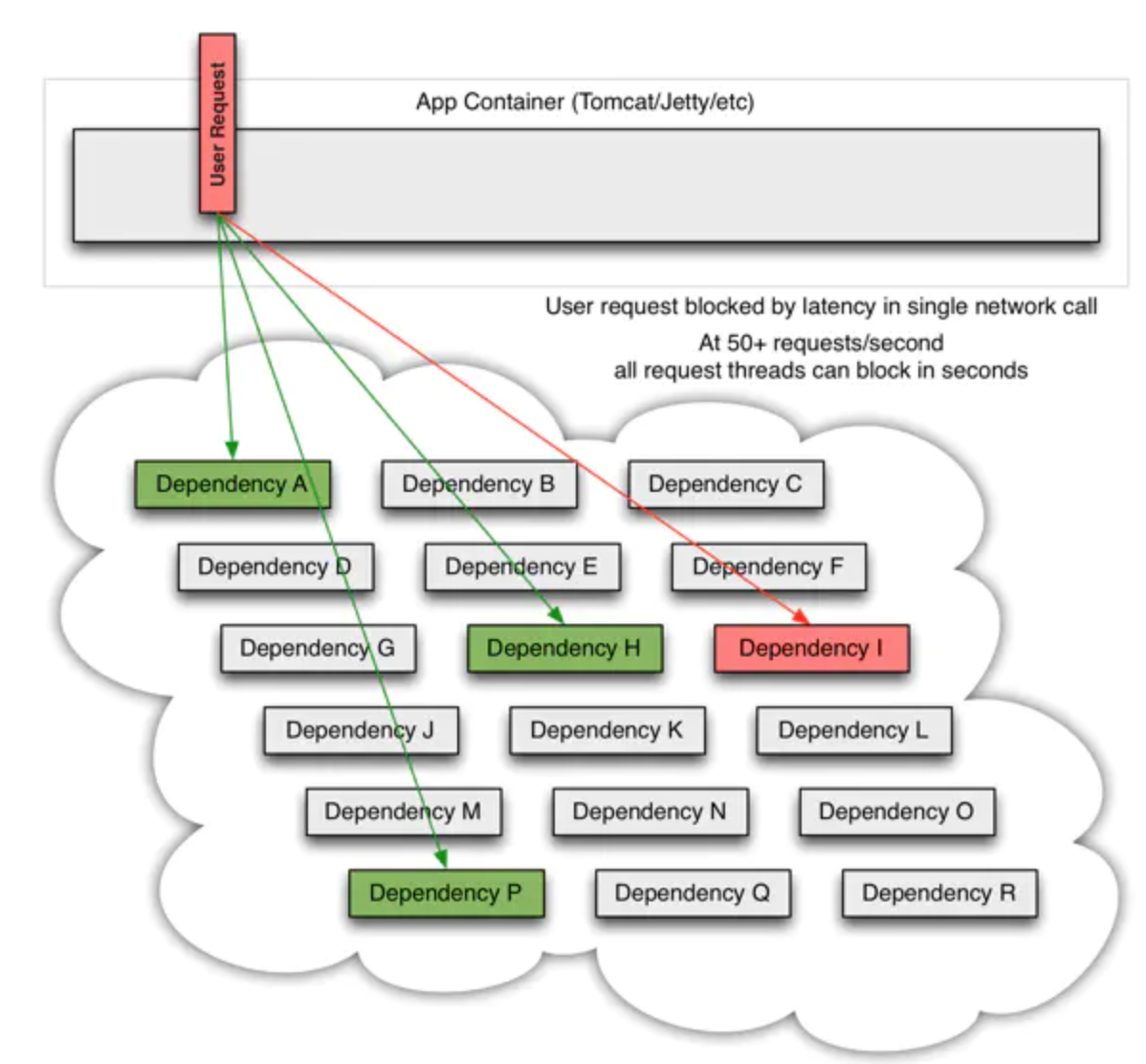
一个高并发后端依赖成为潜在危险时,它会在几秒钟中导致所有服务器上的所有的资源耗尽。
在网络中或者客户端库中运行的每一个app都有可能会导致成为潜在的故障源。比失败更坏的是,这个问题app也可能会导致服务之间的延迟增加,从而备份队列,线程,和其他系统资源,导致更多系统的级联故障。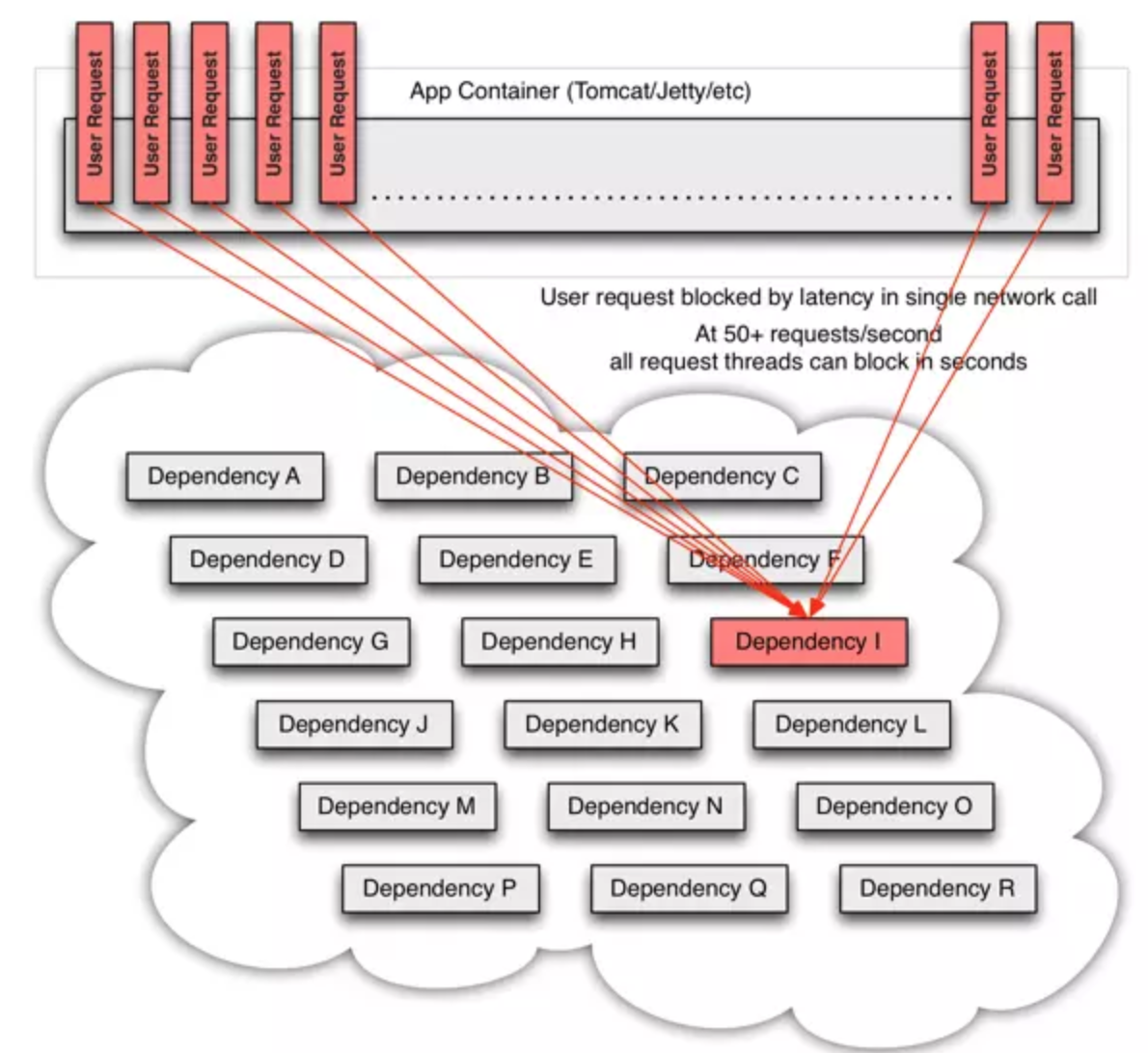
当通过第三方客户端网络访问时,这些问题会加剧,这个第三方客户端就是一个黑盒,其实现细节是不清楚的,它能随时改变行为,每个客户端的网络和资源配置是不同的,通常难以监控和修改。
如果这些网络请求通过第三方客户端发出,问题会变得更加严重,因为这些第三方客户端对于应用来说相当于《黑盒》—无法了解其实现细节,随时可能发生变更,网络/资源配置随客户端的不通而不同,同时又难以监控和修改。同时,应用依赖链中的服务可能非常耗时,或者这些可能导致问题的网络请求根本没有被我们的应用显示的调用!
网络连接可能失败或者降级。服务或者服务器可能失效或者变慢。新依赖的库或者部署的服务可能改变行为或性能,亦或是依赖的客户端库本身有bug。
所有以上这些所描述的失败和延迟都需要被隔离和管理,才不至于因为单个服务失败而导致整个应用活系统垮掉。
上面是Hystrix文档中给我们描述的在多服务系统中由于某个服务的不可用从而会导致整个系统不可用的一种现象。
简单的来说就是由于服务提供者A不可用,导致服务调用者B对A的请求阻塞,没有相关的机制通知或解决请求阻塞,导致在服务调用者B对A请求的阻塞越来越多,阻塞请求变多并且不断对A进行请求重试导致服务调用者B所在的系统的资源会被耗尽,而服务调用者B所在的系统可能并不会只有对A的调用,还有存在对其他服务提供者的调用,因为调用A把系统资源已经耗尽了,导致也无法处理对非A请求,而且这种不可用可能沿请求调用链向上传递,比如说服务调用者C会调用B的服务,因为B所在的系统不可用,导致C也不可用,这样级联导致阻塞请求越来越多,表现为多个系统都不可用了,这种现象被称为”雪崩效应”。
以下内容为互联网资源整理
雪崩效应产生的原因
根据上面的描述,概括一下雪崩效应的过程:服务提供者不可用->服务调用者请求重试->服务调用者所在的系统资源耗尽,服务调用者不可用。
这个过程再概括一下分为三个阶段:
- 服务提供者不可用
- 服务调用者重试
- 服务调用者不可用
服务雪崩的每个阶段都可能由不同的原因造成,下面逐一说明。
服务提供者不可用
服务提供者不可用产生的原因可能有以下几点:
- 硬件故障
如服务器宕机,机房断电,光纤被挖断等。 - 程序Bug
如程序逻辑导致内存泄漏,JVM长时间FullGC等。 - 缓存击穿
缓存击穿一般发生在缓存应用重启, 所有缓存被清空时,以及短时间内大量缓存失效时. 大量的缓存不命中, 使请求直击后端,造成服务提供者超负荷运行,引起服务不可用. - 流量激增
流量激增导致服务提供者无法承受这样的高负载,激增的原因有异常流量,重试加大流量等。
服务调用者重试
在服务提供者出现不可用的情况下,服务调用者重试加大了流量,服务调用者重试又可以分为两种:
- 用户重试
在服务提供者不可用后,用户由于忍受不了界面上长时间的等待,而不断刷新页面甚至提交表单。 - 代码逻辑重试
在代码中请求远端服务时,在出现请求异常的时候,代码逻辑都会有重试的功能,这在因为网路抖动导致请求超时的情况下是很有用的。但是如果本身服务提供者就不可用了,这种不断地重试会加大对服务器提供者的请求流量。
服务调用者不可用
服务调用者不可用产生的原因主要是:
- 同步等待造成的资源耗尽
当服务调用者使用同步调用时, 会产生大量的等待线程占用系统资源。一旦线程资源被耗尽,服务调用者提供的服务也将处于不可用状态。
雪崩效应应对策略
应对策略从造成雪崩的原因出发,提供不同的原因下的解决方案。
- 硬件故障:多机房容灾、异地多活等。
- 程序BUG:修改程序bug、及时释放资源等。
- 缓存穿透:缓存预加载、缓存异步加载等。
- 流量激增:服务自动扩容、流量控制(限流、关闭重试)等。
- 同步等待:资源隔离、MQ解耦、不可用服务调用快速失败等。资源隔离通常指不同服务调用采用不同的线程池;不可用服务调用快速失败一般通过熔断器模式结合超时机制实现。
总结一下就是几个关键词:扩容、流控(流量控制)、隔离、熔断。




