多行合并为一行
现网中经常遇到匹配到某一关键字下的所有行合并到同一行,再次匹配到相关关键字再和下面的合并,示例如下:
# line1
a
b
# line2
c
d
e
# line3
f想要变成:
# line1 a b
# line2 c d e
# line3 f
即:把某个”# line”打头与下一个”#line”打头之间的行合成一行(这一行包括#line),但两个#line之间的行数是不确定的。
以下是发动群众从群里得到的解决方法(分别为sed和awk实现):
# sed实现方法
sed -n '/#/{:a;N;/\n#/{P;D};s/\n//;$p;ta}' file
sed ':a;$!N;/\n#$/!s/\n//;ta;s/#/\n#/g' file
sed -n '1h;/#/!{1!H;$!b};1!{x;s/\n//g;p}' file
# awk实现方法
awk '{printf (/10/&&NR>1)?"\n"$0:$0}' file
awk '/^#10/{if (n++) print ""}{printf $0}' file
awk 'BEGIN{FS="\n";ORS=""};{if($0 ~ /^10/ && NR>1){print "\n"$0;}else{print}}' file
个人还是偏向于使用awk 方法,而且理解上也比较容易理解,sed方法理解起来感觉想当费劲。
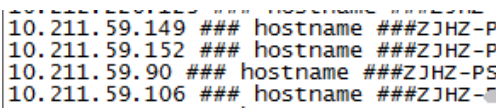
现网需求如下:通过BMC自动化采集工具,采到当前现网某机房挂载某NAS存储的所有主机。通过grep匹配NAS机头IP,有结果输出的证明有挂载,无输出的表明当前未挂载该NAS,输出类似如下图
由于该机房有上千台左右的主机,输出结果还是比较多的。所以想将每台主机的结果主机名等合并到同一行,并通过二次匹配获取所有挂载的主机,这样比较方便导入excel中展示出来。
# awk '/^10/{if (n++) print ""}{printf $0}' caiji.txt |awk '{if($NF!="###"){print $0}}'
由于所有IP都是以10开头的,这里先正则匹配所有10开头的行,如果匹配不上的,通过printf打印并继续向下匹配,匹配上的通过print实现换行。后面的二次匹配就不解释了,比较简单。
注:printf 与 print的区别是printf打印的时候是不会换行的,print打印后,默认是带有\n换行的。如果只打印一行的话,printf + \n = print。
最终输出的结果类似如下: